
Wayback Machine (machine à revenir en arrière ou à remonter dans le temps) est un projet colossal dont l’objectif est d’archiver toutes les pages Web. Il permet de visualiser les versions archivées des pages Web à mesure qu’elles évoluent dans le temps, car bien évidemment tous les sites Web ne sont pas statiques.
À ce jour, l’index de Wayback Machine contient plus de 280 milliards de copies de pages pour un volume de données qui augmente de 20 téraoctets par mois.
L’intérêt est de retrouver des pages Web qui ont disparu de la circulation parce qu’elles ont été définitivement supprimées ou dont le contenu a évolué. Avec ce service, on est à même de ressusciter les pages Web en erreur 404 en remontant dans le passé et même de visiter des sites qui n’existent plus.
Depuis la page d’accueil de Wayback Machine, il suffit de saisir l’adresse d’un site Web ou l’URL d’une page pour accéder à l’archive en ligne qui est présentée sous la forme d’un calendrier.
Des extensions qui s’intègrent aux navigateurs Web ont également été développées pour faciliter les recherches dans les archives : Wayback Machine pour Chrome, No More 404s pour Firefox ou Resurrect Pages pour Firefox. (Lire aussi le billet : 2 extensions Firefox pour retrouver les pages Web disparues).
Le processus d’archivage est intégralement automatisé, mais il faut reconnaître qu’il n’est pas spécialement rapide pour indexer les nouvelles pages.

Ce qu’il faut savoir, c’est qu’il est possible de demander à ce qu’une page Web soit immédiatement ajoutée à l’archive, sans attendre que le robot de Wayback Machine daigne l’explorer.
Cela s’avère utile pour préserver une page Web ou un article susceptible d’être rapidement modifié, pour y accéder à coup sûr à l’avenir, en étant certain que le contenu a été archivé dans sa version originale.
Il est bien entendu toujours possible de sauvegarder une page Web sur son disque dur, mais il est impossible de prouver qu’elle n’a pas été modifiée par la suite. En utilisant l’archive de Wayback Machine, on a la preuve que la page Web archivée est bien la bonne et qu’elle n’a pas été altérée.
Comment ajouter une page Web à Wayback Machine ?
La procédure est très simple, mais elle ne fonctionne que pour les sites Web qui autorisent les robots d’exploration à « crawler » leurs pages.
- Allez sur le site de Wayback Machine
- Localisez la section Save Page Now
- Saisissez ou copiez l’URL de la page Web à archiver dans la zone prévue à cet effet et cliquez sur le bouton Save Page.
- Le processus d’archivage de ladite page est immédiatement lancé.
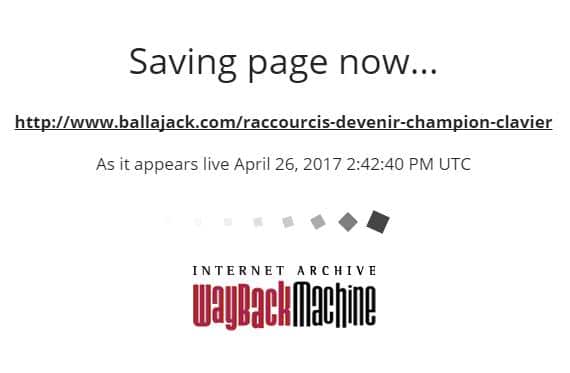
La page en question est chargée avec un indicateur à l’écran qui affiche la progression de l’opération.
Une fois que l’archivage est terminé, on peut accéder à la version archivée de la page Web sur Wayback Machine en copiant son URL depuis la barre d’adresses du navigateur Web.

Il est même possible d’archiver une page Web sans passer par le formulaire en utilisant cette syntaxe : https://web.archive.org/save/http://www.exemple.com/
Remplacez simplement http://www.exemple.com par l’URL de la page Web à capturer.
Pour ceux qui sont des adeptes de la ceinture et des bretelles, l’outil en ligne Archive.is est dans son mode de fonctionnement assez similaire à WayBack Machine.